数据挖掘项目占用时间最多的,不是方法和模型的使用,而是数据的获取和清洗。爬虫则是数据获取的重要途径。今天学习了hadley大神的rvest包,试着爬取北京建委房地产统计数据。
准备工作
- 要爬的网址。 http://www.bjjs.gov.cn/tabid/1210/Default.aspx#9775
- Chrome安装SelectorGadget插件,用于识别网页源代码的区块id
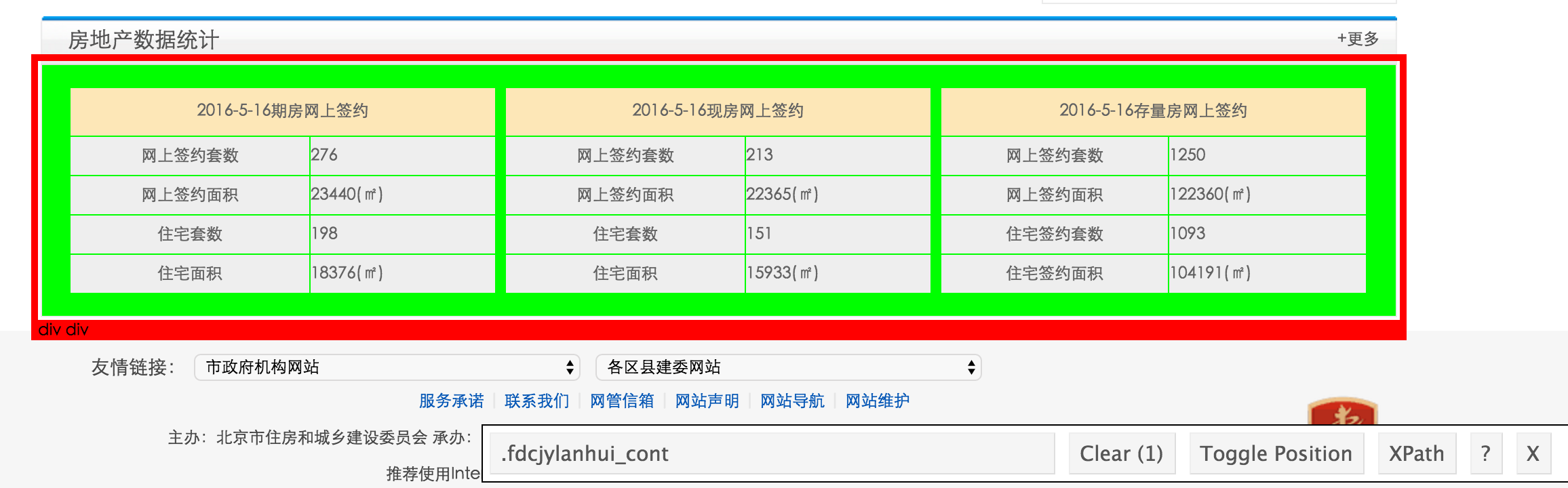
- 使用SelectorGadget识别区块,比如要爬取下图的部分,识别出id为”.fdcjylanhui_cont”
代码实现
1 | library(rvest) |

