2016年对国家来说是不太好过的,但对于我来说是收获颇丰的。首先是收获了爱情,其次是收获了见识。在这一年里发生了很多事,有行业的变化,有工作的变动,也有学习方向的变化。以前的我是个 实践者,表现在实现有意思的、好玩的技术,这个说实话没有什么含量,基本就是模仿;现在的我想要努力的变成一个 思考者,希望自己对生活和工作都多一些思考,多一些自己的见解和想法。
2016年一直在房地产行业,那就谈谈房地产吧
房地产行业的分类
房地产行业分为 新房、二手房、租赁 三部分。
- 新房 是开发商主导的市场。由开发商拿地、开发、新房代理商销售。由于开发商的利润率基本是固定的,所以新房的价格基本上由土地的价格决定
- 二手房 是中介(二手房经纪公司)主导的市场。主要是中介获取房源和客源,然后进行房客的匹配,赚取中介费。二手房的价格是供需关系决定
- 租赁 和二手房类似,也是房客匹配的过程,租赁价格也是供需关系决定
房地产行业的市场
房地产行业市场很大。GMV达16万亿(新房:二手:租赁 = 10:5:1),占GDP的23%,是阿里巴巴GMV的5倍。下图有助于理解房地产市场有多大:
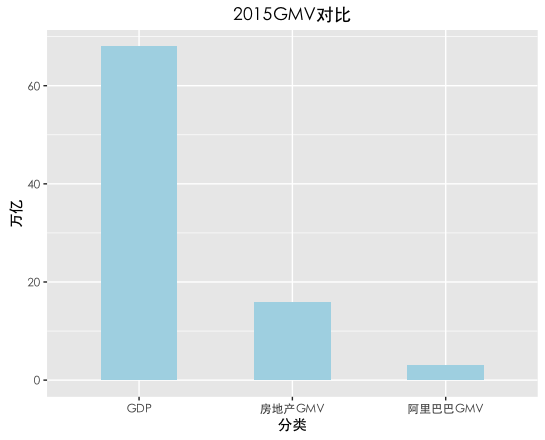
房地产交易总体上是低频、客单价高的市场。大多数人一辈子只买1~2套房,每一次几乎要花掉自己的大部分资产
房地产交易是非标准化的交易。每套房子都有每套房子自己的特点,和标准化的网上购物不一样,房地产不光商品不一样、而且交易的流程也有可能千差万别
房地产行业是服务有待改善的行业。大部分人在租房的时候或多或少都被坑过,对中介怨气连连,在线下的购房环节也有各种各样的不确定因素导致心理的落差,抱怨服务的不好
经纪人是流动性非常大的职位。这一点和其它的销售型岗位类似,离职率非常高,平均年龄都在20多岁
存量房市场以改善型需求为主。学区房、小户型换大户型、近换远
二手房交易
现在大家都在提 存量房时代,二手房交易量/新房交易量 > 1 即代表进入了以二手房为主导的存量市场。一线城市由于对人才的吸引力强导致房屋需求旺盛,土地供应不足导致新房紧张而且地段偏远等原因,已经提前进入了存量房时代。新一线城市也即将进入存量房时代。但是广大的二三四线城市还处于 去库存 的阶段
二手房交易流程
准备买房 -> 看房选房 -> 买卖双方资质审核 -> 签订合同 -> 房屋评估 -> 网签 -> 面签 -> 银行审批 -> 缴税过户 -> 下房本 -> 物业交割 -> 产权抵押银行放款
二手房市场的影响因素
- 整体而言,影响二手房交易量和交易价的主要因素是供需关系,以下因素都在影响供需关系:
- M2:国家印钞多了,持有大量货币的人为了避免通货膨胀,会把钱投入到相对保值的房地产市场
- 土地:地王会通过改变人们心理预期的方式来影响周围的房价
- 政策:限购政策(外地5年社保一套、本地单身一套、家庭二套)、限贷政策(银行限制贷款给开发商、提高购房人的首付比例、首套二套的认定标准)
- 利率:贷款利率的高低影响还贷额
- 缴税:影响买方购房能力
- 汇率:影响钱的流向
- 对单个房屋而言,影响价格的主要因素是房屋的位置,比如是不是学区房、位于哪个区域、周边配套怎么样。地铁主要影响的是租赁的价格
PS:供需关系还分结构,比如分面积段、居室段、价格段等。房地产市场的供需关系不太稳定,拿需求讲有强需求(现在必须买)、一般需求(什么时候买都行)、弱需求(买或不买都可以),导致预测房价困难很大
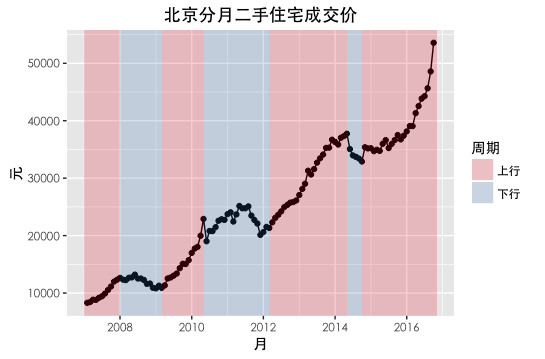
二手房市场周期
我的贡献
- 前期数据库的建设:主要有新增房、新增客、存量、带看、调价、成交、贷款、税费等数据,还包括一些wind的数据,取数用
WindR包,详情参见R连接Wind数据库 - 报表的制作:主要由
DT、shiny、RMySQL、dplyr实现,基本是数据处理的操作 - 换房轨迹和看房轨迹(以小区为单位):主要由
REmap、leaflet实现,主要是看用户为什么换房、用户去哪里;客户看房热点、路线及所看房屋的特征,详情参见REmap(0.3.2)有个bug~ - 词云:热点商圈、小区等:
wordcloud2实现,参见附录 - 不同年代客户特征,参见附录
- 简单的爬虫实现,参见附录
- R语言入门beamer,参见R语言入门.pdf
- 年初的自动化报告,参见线下城市新增房源核实.pdf
- 年初的薪酬绩效测算回报,基本是照猫画虎的,参见《薪酬设计与绩效考核全案》,2013年赵国军版
- 30篇博客,参见http://www.xinyao.pub/archives/
附录
词云
比如北京2016年1~9月的热门楼盘:

mydata3数据有两列,一列是楼盘名称、一列是成交量
1 | library(wordcloud2) |
不同年代客户特征
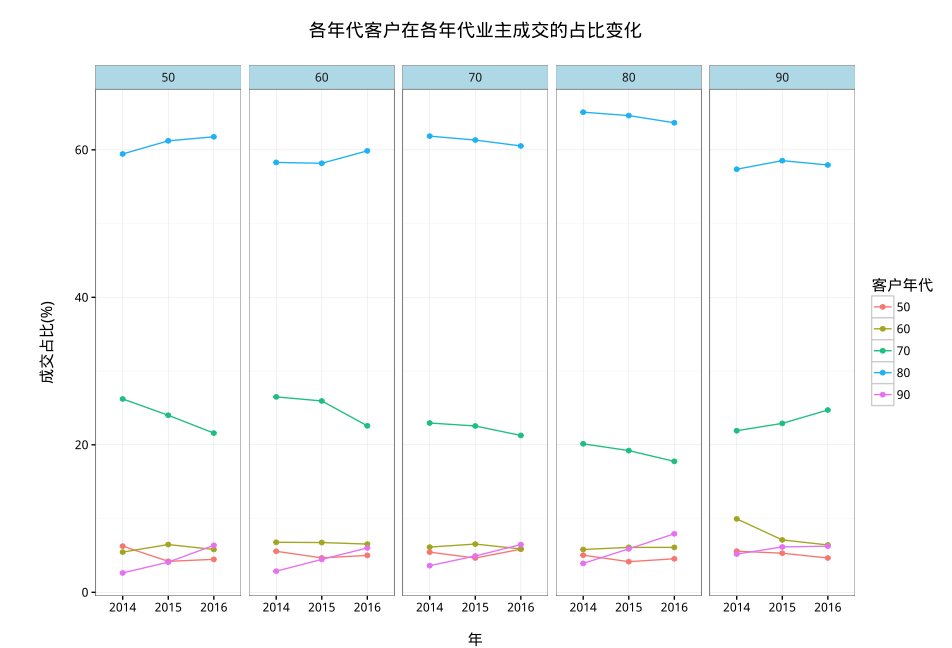
- 50、60、70后购房需求逐渐减弱
- 80后是现阶段购房的主力军
- 90后的接盘能力逐渐变强
80后主要从50、60后手里购入了学区房
客户年代为 80后 :
| 年份 | 业主年代 | 活跃楼盘 |
|---|---|---|
| 2014 | 50 | 模式口西里;育新花园;芍药居北里 |
| 2015 | 50 | 芍药居北里;康静里;松榆西里 |
| 2016 | 50 | 模式口西里;芍药居北里;慧忠里 |
| 2014 | 60 | 育新花园;北京像素北区;车站北里 |
| 2015 | 60 | 芍药居北里;荣丰2008;育新花园 |
| 2016 | 60 | 北广家园;芍药居北里;海特花园小区 |
- 模式口西里:学区房。石景山小学
- 育新花园:学区房。首都师范大学附属育新学校小学部
- 芍药居北里:学区房。中国人民大学附属中学朝阳学校小学部
- 康静里:学区房。北京师范大学奥林匹克花园实验小学
- 慧忠里:学区房。北京市朝阳外国语学校慧忠里校区
- 车站北里:学区房。北京市大兴区第八小学
- 荣丰2008:学区房。北京小学天宁寺分校
- 北广家园:学区房。北京市西城区五路通小学
- 松榆西里:学区房。垂杨柳中心小学
- 海特花园小区:学区房。海特小学
70后主要从90后手里购入了高端房
客户年代为 70后 :
| 年份 | 业主年代 | 活跃楼盘 |
|---|---|---|
| 2014 | 90 | 龙湖唐宁one;万年花城四期;新中关公寓 |
| 2015 | 90 | 万达大湖公馆;保利茉莉公馆;宝石花苑 |
| 2016 | 90 | 观湖国际;天创世缘;银河湾 |
上述小区都是偏豪宅化的
简单的爬虫实现
关于爬虫,以前写过一个关于rvest的博客:rvest爬取简单的网页信息
现在更新一个爬取 城市天气信息 的代码,网址是 http://lishi.tianqi.com/
1 | library(RCurl) |
取出城市的链接地址,把所有的链接地址都处理成类似http://lishi.tianqi.com/beijing/的格式
1 | linklist = linklist[str_detect(linklist,"/index.html")] #获取城市的链接 |
生成类似201610.html的序列
1 | datelist = seq.Date(as.Date("2011-01-01"), |
生成类似http://lishi.tianqi.com/beijing/201610.html的序列,3000多个城市和地区的每月天气网址都大同小异
1 | url_list = NULL |
解析网址
1 | # 解析网址 |
mydata即为生成的数据框,包括7列,日期、最高气温、最低气温、天气、风向、风力、城市。从2011年开始至2016年11月,一共200多万条数据
1 | for(i in 1:length(mydata$data)){ |
上述代码是我初学时写的,质量不高,以后有时间进行优化
17年计划简陋版
- 仔细研究周志华的《机器学习》,把每个算法都弄清楚,并且用R进行实现
- 了解市场和行业,用机器学习的方法得出有意思的结论
- 对博客进行进一步的整理完善

